Showing
- bindings/java/doxygen/datasources.dox 33 additions, 0 deletionsbindings/java/doxygen/datasources.dox
- bindings/java/doxygen/docs/jni-docs/.gitignore 4 additions, 0 deletionsbindings/java/doxygen/docs/jni-docs/.gitignore
- bindings/java/doxygen/footer.html 7 additions, 0 deletionsbindings/java/doxygen/footer.html
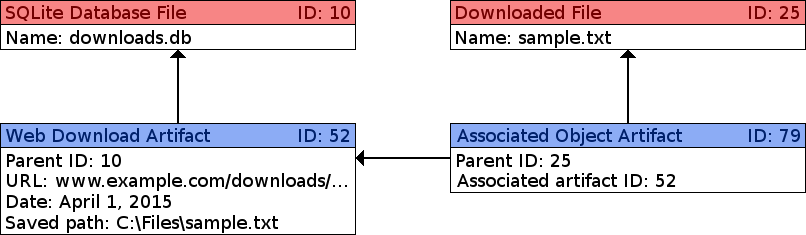
- bindings/java/doxygen/images/associated_object.png 0 additions, 0 deletionsbindings/java/doxygen/images/associated_object.png
- bindings/java/doxygen/images/json_attribute.png 0 additions, 0 deletionsbindings/java/doxygen/images/json_attribute.png
- bindings/java/doxygen/insert_and_update_database.dox 19 additions, 0 deletionsbindings/java/doxygen/insert_and_update_database.dox
- bindings/java/doxygen/main.dox 58 additions, 0 deletionsbindings/java/doxygen/main.dox
- bindings/java/doxygen/os_accounts.dox 130 additions, 0 deletionsbindings/java/doxygen/os_accounts.dox
- bindings/java/doxygen/query_database.dox 160 additions, 0 deletionsbindings/java/doxygen/query_database.dox
- bindings/java/doxygen/schema/db_schema_8_6.dox 378 additions, 0 deletionsbindings/java/doxygen/schema/db_schema_8_6.dox
- bindings/java/doxygen/schema/db_schema_9_0.dox 7 additions, 0 deletionsbindings/java/doxygen/schema/db_schema_9_0.dox
- bindings/java/doxygen/schema/db_schema_9_1.dox 557 additions, 0 deletionsbindings/java/doxygen/schema/db_schema_9_1.dox
- bindings/java/doxygen/schema/schema_list.dox 17 additions, 0 deletionsbindings/java/doxygen/schema/schema_list.dox
- bindings/java/ivy.xml 27 additions, 0 deletionsbindings/java/ivy.xml
- bindings/java/ivysettings.xml 9 additions, 0 deletionsbindings/java/ivysettings.xml
- bindings/java/jni/.indent.pro 1 addition, 0 deletionsbindings/java/jni/.indent.pro
- bindings/java/jni/Makefile.am 13 additions, 0 deletionsbindings/java/jni/Makefile.am
- bindings/java/jni/auto_db_java.cpp 2015 additions, 0 deletionsbindings/java/jni/auto_db_java.cpp
- bindings/java/jni/auto_db_java.h 241 additions, 0 deletionsbindings/java/jni/auto_db_java.h
- bindings/java/jni/dataModel_SleuthkitJNI.cpp 2355 additions, 0 deletionsbindings/java/jni/dataModel_SleuthkitJNI.cpp
Some changes are not shown.
For a faster browsing experience, only 20 of 137+ files are shown.
bindings/java/doxygen/datasources.dox
0 → 100644
bindings/java/doxygen/footer.html
0 → 100644
{kind=link}
23 KiB
{kind=link}
55.9 KiB
bindings/java/doxygen/main.dox
0 → 100644
bindings/java/doxygen/os_accounts.dox
0 → 100644
bindings/java/doxygen/query_database.dox
0 → 100644
bindings/java/doxygen/schema/schema_list.dox
0 → 100644
bindings/java/ivy.xml
0 → 100644
bindings/java/ivysettings.xml
0 → 100644
bindings/java/jni/.indent.pro
0 → 100644
bindings/java/jni/Makefile.am
0 → 100644
bindings/java/jni/auto_db_java.cpp
0 → 100644
bindings/java/jni/auto_db_java.h
0 → 100644
bindings/java/jni/dataModel_SleuthkitJNI.cpp
0 → 100644